Cada vez que circulan fotografías, videos o audios impactantes surge la misma pregunta: ¿son reales o fueron creados con inteligencia artificial (IA)? Para los habitantes de Europa y California, una parte de esa respuesta estará mucho más cerca a partir del 2 de agosto.
Ese día entrarán en vigor las primeras regulaciones que obligarán a informar al público sobre el papel que desempeñó la IA en la generación o manipulación de contenidos digitales. Además, ya existen indicios de que estas normas podrían influir en otras jurisdicciones del mundo.
Sin embargo, saber que un contenido fue generado o modificado mediante IA no resuelve, por sí solo, los problemas de la desinformación ni la pérdida de confianza del público en la información que consume. Sigue existiendo una gran cantidad de contenidos capturados y manipulados de forma artesanal por personas.
De hecho, algunos especialistas advierten que etiquetar únicamente los contenidos generados con IA -una suerte de «etiqueta de nutrición digital»- podría distorsionar la percepción del público sobre el resto de los contenidos que circulan. En esta etapa de transición, la respuesta será necesariamente parcial y presentará desafíos.
A partir de esa fecha, las principales empresas desarrolladoras de IA deberán ofrecer al público herramientas que permitan responder a una pregunta cada vez más frecuente: ¿este contenido fue generado por IA? Muchas compañías, entre ellas Google, OpenAI, Microsoft y Meta, ya comenzaron a avanzar en esa dirección.
En California, la obligación surge de la Ley de Transparencia de IA del estado, mientras que en Europa se establece en el artículo 50 de la Ley de Inteligencia Artificial.
En la antesala de esta fecha clave, coordinada entre ambas jurisdicciones, investigadores del norte de Europa publicaron un estudio que mostró que la confianza del público en las marcas periodísticas aumentó cuando estas incorporaban etiquetas digitales de procedencia en las imágenes informativas.
«Mostramos que enfatizar la veracidad del contenido mediático mediante etiquetas de procedencia mejora la credibilidad del contenido, lo que, a su vez, fortalece la confiabilidad de la fuente (Fisher, 2016)», señalaron los cuatro autores del estudio, pertenecientes a MediaFutures, el Centro de Investigación para Tecnología e Innovación de Medios Responsables de la Universidad de Bergen (Noruega), y a la Escuela de Investigación en Comunicación de la Universidad de Ámsterdam.
«En particular, comprobamos que la información de procedencia tiene un mayor impacto en la confianza hacia aquellas fuentes periodísticas que inicialmente eran percibidas como menos confiables. Probablemente esto se deba a que existe un mayor margen para fortalecer esa confianza en comparación con medios altamente reputados, como BBC News», agregaron los investigadores en el resumen del trabajo.

Gran parte de la legislación que hoy avanza en distintos países se limita, por ahora, a exigir transparencia sobre el origen de los contenidos sintéticos generados mediante inteligencia artificial. Sin embargo, California fue más allá: la norma prevé que los creadores de contenidos reales también puedan incorporar, de manera voluntaria, etiquetas de procedencia, como etapa final de una transición hacia un ecosistema digital más transparente.
Incluso en California, la incorporación de metadatos y etiquetas para los contenidos auténticos constituye el último paso de un proceso destinado a construir un ecosistema con información integral sobre el origen de los contenidos digitales.
Christoph Trattner, profesor de la Universidad de Bergen y uno de los autores del estudio sobre confianza del público, explicó a Convercom.info que etiquetar únicamente los contenidos generados por IA, y no también los auténticos, podría generar consecuencias no deseadas.
«Uno de los riesgos durante este período de transición es que el público comience a interpretar la ausencia de una etiqueta como una prueba de que el contenido es auténtico», señaló en respuestas enviadas por correo electrónico.
El investigador agregó que las credenciales de contenido no deberían entenderse simplemente como «etiquetas de IA», ya que un contenido sin identificación no es necesariamente auténtico ni ha sido verificado.
«El valor de largo plazo de estas etiquetas de procedencia radica en comunicar todo lo que se conoce sobre el origen y el historial de edición de un contenido, independientemente de si fue generado sintéticamente o capturado en el mundo real», afirmó Trattner. «De lo contrario, el sistema podría crear inadvertidamente una falsa dicotomía entre una ‘IA etiquetada’ y una ‘realidad sin etiquetar’.»
Según el académico noruego, para que el sistema funcione correctamente, las etiquetas deberían estar presentes en todo tipo de contenidos. De ese modo, los usuarios podrían evaluar el grado de confianza que les merece cada pieza informativa en función de la calidad y la cantidad de datos disponibles sobre su procedencia.
«Desde mi punto de vista, el camino a seguir requiere una adopción mucho más amplia por parte de las cámaras, las herramientas de edición y las plataformas de distribución. También exige comunicar con mayor claridad qué significa -y qué no significa- la ausencia de una etiqueta, además de desarrollar interfaces que ofrezcan un resumen comprensible para el público general, sin impedir que periodistas y usuarios avanzados puedan examinar el registro completo de procedencia», concluyó.
Más allá de la entrada en vigor de estas regulaciones, ya existe un conjunto de iniciativas que anticipan un ecosistema digital con cada vez más información sobre el origen y la naturaleza de los contenidos.
Si bien algunas empresas desarrollaron soluciones propias -como SynthID de Google o las marcas de agua incorporadas en los servicios de IA de Alphabet-, la mayoría de los avances convergen en el estándar impulsado por la Coalición para la Procedencia y Autenticidad de los Contenidos (C2PA), con el respaldo de la Iniciativa para la Autenticidad de los Contenidos (CAI), una alianza integrada por más de 6000 organizaciones de distintos sectores de la actividad económica (a la que Convercom.info adhirió en 2022).
El estándar C2PA cumple con los requisitos establecidos por las regulaciones de Europa y California, ya que es interoperable, confiable, robusto y ampliamente adoptado por los distintos actores del ecosistema digital. Aunque no es mencionado de manera explícita en los textos legales, durante el proceso de elaboración de las normas fue reconocido como el único estándar que actualmente satisface esos requisitos.
Durante el primer semestre de este año, tanto Google como OpenAI anunciaron herramientas para que sus usuarios puedan detectar la información de procedencia incorporada a los contenidos generados por sus sistemas. En el caso de Google, esa función estará disponible a través de Gemini y, próximamente, también mediante Chrome y su motor de búsqueda. OpenAI, en tanto, incorporó un hipervínculo específico para acceder a esa información.
Google también informó que Meta -con la que comparte responsabilidades en el comité directivo de C2PA- comenzará a mostrar en Instagram la información de procedencia generada por cámaras compatibles con ese estándar, como el Pixel 10, el primer teléfono de la compañía que lo incorpora de forma nativa.
Al anunciar estas medidas, Laurie Richardson, vicepresidenta de Confianza y Seguridad de Google, reafirmó el compromiso de la empresa con la adopción de C2PA como estándar global.
«Cada vez utilizamos Credenciales de Contenido C2PA en más herramientas de medios generativos. Se trata del estándar de la industria que permite conocer cómo fue creado y modificado un contenido, con o sin inteligencia artificial», afirmó Richardson. «El Pixel 10 fue el primer smartphone en ofrecer Credenciales de Contenido para imágenes desde su aplicación nativa de cámara y, próximamente, ampliaremos esta tecnología para incluir video en los teléfonos Pixel 8, 9 y 10.»
Los avances anunciados por Google y OpenAI están alineados con las regulaciones que comenzarán a regir en California y Europa, aunque ya se encuentran disponibles para usuarios de numerosos países que aún no cuentan con ese tipo de legislación.
Durante el primer semestre de 2026, la Coalición por la Transparencia -una organización que monitorea la evolución de la legislación vinculada con la inteligencia artificial en Estados Unidos- presentó cuatro modelos de proyectos de ley para abordar distintos aspectos regulatorios. Uno de ellos propone la obligatoriedad de marcar y etiquetar los contenidos generados mediante IA, en términos muy similares a las normas ya aprobadas en los estados de Arizona y Washington.
«La desinformación, el engaño, el fraude y la difamación en línea se han multiplicado desde la aparición de las herramientas de inteligencia artificial generativa», señaló la Coalición por la Transparencia al fundamentar la necesidad de este modelo legislativo. En la conclusión del documento agregó: «Exigir que las imágenes y los videos generados mediante IA sean identificados constituye una medida de sentido común que puede implementarse con la tecnología disponible en la actualidad».
Fechas regulatorias clave
- 2 de agosto de 2026: entran en vigor la Ley de Transparencia de IA de California y las disposiciones de la Ley de Inteligencia Artificial de la Unión Europea, en particular su artículo 50.
- La entrada en vigor de la norma californiana, prevista originalmente para el 1.º de enero de 2026, fue postergada hasta el 2 de agosto para coincidir con la aplicación de la regulación europea.
- A partir de esa fecha, los sistemas de inteligencia artificial que generen contenidos digitales deberán incorporar información de procedencia y ofrecer a los usuarios herramientas que permitan verificar si un contenido fue creado mediante IA.
- 1.º de enero de 2027: la Ley de Transparencia de IA de California obligará a plataformas digitales y redes sociales a mostrar o facilitar el acceso a la información de procedencia cuando esta acompañe a un contenido digital.
- 2 de febrero de 2027: la Ley 1786 del Senado del estado de Arizona, ya aprobada y promulgada por el gobernador, obliga a los servicios de inteligencia artificial generativa con domicilio en ese estado a incorporar información de procedencia en los contenidos de imagen, video y audio que produzcan.
- Ese mismo día también entrará en vigor la Ley 1170 del estado de Washington, aprobada y promulgada por el gobernador, que exige a los servicios de IA generativa identificar los contenidos de audio, video e imágenes cuando ello sea técnica y comercialmente viable, además de poner a disposición del público herramientas para verificar esa información de procedencia.
- 1.º de enero de 2028: la Ley de Transparencia de IA de California obligará a los fabricantes de dispositivos de captura —cámaras fotográficas, cámaras de video y grabadores de audio— radicados en ese estado a incorporar la tecnología necesaria para identificar los contenidos mediante metadatos, marcas de agua u otros mecanismos de información de procedencia.
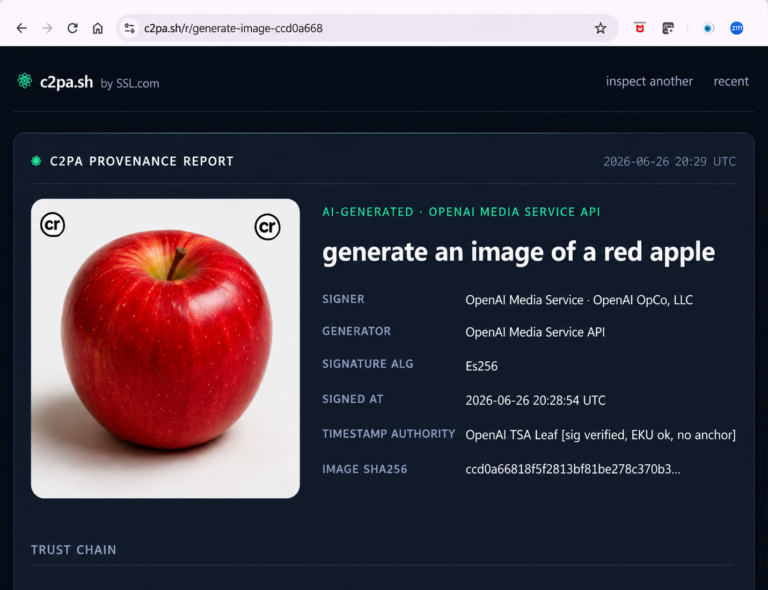
Herramientas para verificar credenciales de contenido C2PA
Estas plataformas permiten comprobar la presencia de credenciales de contenido C2PA para determinar el origen de imágenes, ya sea que hayan sido generadas mediante inteligencia artificial o capturadas con cámaras compatibles con el estándar C2PA.
- C2PA Viewer (SSL.com): permite generar una imagen con OpenAI y visualizar las credenciales de contenido incorporadas para verificar su procedencia.
- Content Authenticity Initiative (CAI): herramienta de la Iniciativa para la Autenticidad de los Contenidos que permite inspeccionar las credenciales de procedencia de imágenes y otros contenidos digitales.
- OpenAI Verify: servicio de OpenAI para verificar la información de procedencia incorporada a los contenidos generados por sus modelos.
- Adobe Content Authenticity: permite inspeccionar las credenciales de contenido de imágenes digitales. Además, desde aquí los autores pueden firmar digitalmente sus fotografías para acreditar su autoría e indicar que esas obras no sean utilizadas para el entrenamiento de modelos de inteligencia artificial.
Ayudanos a seguir pensando, buscando y elaborando información para conectar a la sociedad. Si valoras lo que hacemos....




Hacé tu comentario